- Es gibt eine Vorlesungsaufzeichnung vom WS11/12 über den Streaming-Client der ATIS.
- Einordnungskriterien ML
- Die Inhalte dieser Zusammenfassung beziehen sich vorallem auf die Themengebiete von Herrn Professor Zöllner
- Es besteht keinerlei Anspruch auf Vollständigkeit oder Richtigkeit
Allgemeines
- Wahrscheinlichkeitsverteilung ist stationär wenn sich nicht über die Zeit ändert.
Einordnungskriterien von Lernverfahren

Typ der Inferenz
- Induktiv: Aus Trainingsbeispielen auf ein allgemeines, dahinter liegendes Konzept schließen (Version Space- Algrotithmus)
- Deduktiv: Vorhandenes generelles Wissen wird eingesetzt um spezielle Regeln für Trainingsbeispiele zu bestimmen (Erklärungsbasierte Generalisierung)
Ebene des Lernens
- Symbolisch: Ein Teil der Semantik der Daten erkennbar und Lernverfahren macht davon explizit Gebrauch (Entscheidungsbäume)
- Subsymbolisch: Lernverfahren fasst Daten als Signale auf, z. Bsp. Reelle Zahlen (Neuronale Netze)
Lernvorgang
- Überwacht: Trainingsbeispiele haben bereits zugehörige Klassen annotiert (k-Nearest Neighbor)
- Unüberwacht: Ohne Klassenzugehörigkeit (k-Means)
Beispielgebung
- inkrementell: Trainingsbeispielle können einzeln in das System eingegeben werden und das System verfeinert mit jedem Beispiel seine Hypothese (bereits eingelernte Trainingsdaten müssen dafür nicht nochmal betrachtet werden (ID5R)
- nicht inkrementell: Hinzunahme zusätzlicher Trainingsbeispiele erneut die ursprünglichen mitverarbeiten (ID3)
Umfang der Beispiel
- umfangreich: vier/fünfstellige Zahlen (Neuronale Netze)
- gering: eine Hand voll Beispiele (Case-Based-Reasoning)
Hintergrundwissen
- empirisch: statistisch ausgewertetes Erfahrungswissen (SVMs)
- axiomatisch: logischer Unterbau des Lernverfahrens mit echten formalen logischen Ableitungen (Erklärungsbasierte Generalisierung)
Definition Maschinelles Lernen
Ein System lernt aus Erfahrung E in Hinblick auf eine Klasse von Aufgaben T und einem Performanzmaß P, wenn seine Leistungen bei Aufgaben aus T gemessen mit P durch Erfahrung aus E steigt.
Komponenten eines lernenden Systems

Inferenz
Deduktiver Schluss
Aus einer Menge von Formeln A folgt B <=> Es gibt eine Folge von Regeln, um B abzuleiten.
Abduktion
H folgt aus Hintergrundwissen B und Beobachtungen D abduktiv d.h. mit Ableiten der Prämisse aus Hintergrundwissen und Beispiel
Induktiver Schluss
Geg. eine Menge D von Grundbeispielen. Die Hypothese H folgt induktiv aus D und dem Hintergrundwissen B. Aus Hypothese einzelne Beispiele ableitbar, aber nicht umgekehrt
Wissensrepräsentation
- Assoziative Paare bestehend aus Ein und Ausgangsvariablen
- Parameter in algebraischen Ausdrücken z. Bsp. Gewichtsmatrix
- Entscheidungsbäume
- Formale Grammatiken
- Produktionsregeln
- Logik-basierte Ausdrücke
- Graphen und Netzwerke
- Frames, Schemata, Semantische Netze (größer als einzelne logische Ausdrücke/Produktionsregeln)
- Prozedurale Kodierung z. Bsp Automatische Programmiersysteme, motorische Fähigkeiten
- Taxonomischen (Hierarchische Klassifikation, Lernen durch Beobachtung.
- Markov Ketten als Repräsentation von Hintergrundwissen.
- Mischformen aus verschiedenen Repräsentationsarten
Lernprozess

- (1+2) Erkkennen der Aufgabe, Menge der gewünschten Aktivitäten spezifizieren, Datensammlung (Trainingssequenz)
- (3) Segmentierung manuell durch Benutzer und Labelling
- (4 + 5) Auswahl der SVM + Parameter, Eigentliches Training zur Bestimmung der Support Vektoren
- (6 + 7) Bewertung anhand gelabelter Sequenzen und Erkennungsrate, Verfeinerung durch zusätzliche Sequenzen / Trainingsergänzung
Induktives Lernen
- Was ist Induktion? Prozess des plausiblen Schließens vom Speziellen zum Allgemeinen.
Induktion vs. Deduktion
Induktion: Wahrheitserweiternd, Macht Lebewesen überlebensfähig, Plausibilität
Deduktion: Wahrheitserhaltend, Logischer Schlüss, Korrektheit
Induktive Lernverfahren
- Induktive Lernhypothese: Jede Hypothese, die die Zielfunktion über einer genügend großen Menge von Trainingsdaten gut genug approximiert, wird die Zielfunktion auch über unbekannten Daten gut approximieren.
- Instanzraum:
X - Trainingsmenge
D = x_1, .., x_n in X - Zielkonzept:
c - Hypothesenraum:
H - Konzept: Untermenge von Objekten/Ereignissen defniert auf größerer Menge (boolsche Fkt ob in Menge)
- Konsistenz: Keine negativen Beispiele werden positiv klassifiziert.
- Vollständigkeit: Alle positiven Beispiele werden als positiv klassifiziert.

- Konzeptlernen: Schließen auf die boolsche Fkt. aus Trainigsdaten
General to Specific
(Wird weniger behandelt)
- Ausgangspunkt ist allgemeinste Hypothese
<?,..,?> - Negative Beispiele: Spezialisierung
- Positive Beispiele: werden nicht betrachtet
Specific to General
- Ausgangspunkt ist speziellste Hypothese
<#,..,#> - Negative Beispiele: werden nicht betrachtet
- Positive Beispiele: Immer minimalste Verallgemeinerung anwenden
Bewertung
- Wichtig
- Für Menge der Hyopthesenräume, die durch Konjunktionen von Attributeinschränkungen beschrieben sind ist garantiert, dass das Verfahren die spezifischste Hypothese findet, die mit den positiven Trainingsbeispielen vereinbar ist.
- Endhypothese ist mit negativen Trainingsdaten konsistent falls:
- Trainingsdaten korrekt
- Zielhypothese in
Henthalten - Offen:
- Trainingsdaten konsistent?
- Endkonzept = korrektes Zielkonzept?
- Warum spezifischste Hypothese?
Präzedenzgraphen
Ziele
- Anwendung z. Bsp. bei Servicerobotern
- Intuitive Benutzerschnittstelle (Vorführen, Beobachten, Lernen)
- Umordnung von Teilaufgaben (Optimierung, Lernen von Vorrangsbeziehungen)
- Lernen sequentieller Unabhängigkeiten
- Mehrere Durchläufe
- Identifikation äquivalenter Teiloperationen und deren (Un)abhängigkeiten
Definition
- Codierung der Hypothesen
- DAG (directed acyclic graph)
P = (N,E) - Kanten = Vorrangsbeziehung (
E= Edges) - Genereller-als-Beziehung
Version Space / Candidate Elimination Algorithmus
Paralleles Anwenden von General to Specific und Specific to General
Definition: Versionsraum (Version Space)
- Menge von konsistenten Hypothesen, Intervall in der partiellen Ordnung „spezieller als“ auf dem Hypothesenraum
VS_{H,D}bezüglich des Hypothesenraums H und der Menge von Trainingsbeispielen D ist die Untermenge der Hypothesen von H, die mit den Trainingsbeispielen in D konsistent ist.
Algorithmus
- Gespeichert werden folgende Mengen, die alle Beispiele abdecken (-> Hypothesen müssen nicht alle gespeichert werden):
- Menge der speziellsten Hypothesen
S, initial:S = {#} - Menge der allgemeinsten Hypothesen
G, intitial:G = {?} - Beispiel
bist negativ Beispiel: - Lösche aus
Sdie Hypothesen diebabdecken - Spezialisiere die Hypothesen in
Gsoweit, dass siebnicht abdecken und dass sie allgemeiner als eine Hypothese inSbleiben - Lösche aus
Galle Hypothesen die spezifischer als eine andere Hypothese ausGsind. - Beispiel
bist positiv Beispiel: - Lösche aus
Gdie mitbinkonsistenten Hypothesen - Verallgemeinere die Hypothesen in
Ssoweit, dass diebabdecken und dass sie spezifischer als eine Hypothese inGbleiben - Lösche aus
Salle Hypothesen, die allgemeiner als eine andere Hypothese ausSsind
Einordnung

Bewertung
- Version Space konvergiert zur korrekten Hypothese (
S = G) - Wenn Beispiele konsistent, korrekte Hypothese in H enthalten
- Probleme:
- Fehlerhafte Trainingsdaten (Rauschen)
- Zielkonzept nicht von Hypothesenrepräsentation abgedeckt (-> Erweiterung via disjunkte Begriffe??)
- Attributgeneralisierungsregeln maßgebend für Lernerfolg
- Positiv:
- Kein Speichern alter Beispiel notwendig
- Stellt fest, wann genügend Beispiele gegeben wurden (
S = G)
Induktiver Bias
- Induktion bescheibt die Verallgemeinerung auf Basis von Beispielen, aber der Hypothesenraum spielt auch eine wesentliche Rolle (Beispiel mit einseitig schwarzem Schaf (Ziege)) -> Zielkonzept nicht im Hypothesenraum
- Ein induktives Lernsystem, das keine a priori-Annahmen über die Identität des Zielkonzepts macht, hat keine rationale Basis, um unbekannte Instanzen zu klassifizieren. -> Funktioniert nicht ohne Vorannahme!
Bias (Vorzugskiterium)
Vorschrift nach der Hypothesen gebildet werden.
Mögliche Vorzugskriterien
- Verständlichkeit (für Mensch)
- Klassifikationsgenauigkeit
- Messaufwand für die verwendeten Deskriptoren
- Berechnungs- und Speicheraufwand für Hypothese
-
Hypothesenraumbias (h gehöre zu einem beschränkten Raum von Hypothesen)
- Komplexität des Hypothesenraums
- Beispiele
- logische Konjunktion
- lineare Schwellwertfunktion
- Gerade, Polynome
-
x-Nearest Neighbour
-
Präferenzbias
- Ordnung auf dem Raum der Hypothesen
- Wähle Hypothese mit höchster Präferenz
- Wähle h welcher möglichst viele Beispiele richtig Klassifiziert
Vergleich induktiver Lernsysteme anhand ihres inductive bias
- Auswendiglerner: keine Vorannahme
- Version Space: Zielkonzept kann im Hypothesenraum repräsentiert werden
- Specific-to-General Lerner: Wie Version Space + alle Instanzen sind initial negative Instanzen bis Gegenteil bekannt
Je strenger Vorannahmen desto mehr können unbekannten Daten klassifiziert werden
Je strenger die Vorannahmen sind desto konsistenter ist die Klassifikationsentscheidung (-> weniger false-positives)
Lerntheorie
(Zöllner)
Löse nie ein Problem komplizierter als nötig, denn die einfachste, richtige Erklärung ist die Beste (Rasiermesser-Prinzip von Occam)
Lernen = Schätzen einer Abbildung (Hypothese) mit Hilfe von (bekannten) Beispielen (Lernbeispiele) generiert von einem (nicht bekannten) System mit der Wahrscheinlichkeit P.
Definition Lernmaschine
h_aHypothese mit Parametera- Lernende Maschine ist bestimmt aus
- Hypothesenraum
{h_a : a in A}(implementiert diesen) - Lernverfahren: Methode um
a_optmit Hilfe von Lernbeispieken zu finden (Fehlerfkt, Optimierung) - Resultierendes (Entscheidungs-) Modell
M_optgegeben durch - Auswertung der optimalen Hypothese
h_a_optdie durch die lernen(den) Maschine(n) bestimmt wird
Welche Maschine wählen (Welches Lernverfahren)?
Welches Modell?
Lerntypen
- Konzeptlernen: Attributmenge
A_1, .., A_n->true/false - Klassifikation (numerisch):
R^N->Klasse_1, .., Klasse_n - Regression (numerisch):
R^N->R
Probleme beim Lernen
- Statistisches Problem: Bezügl. Trainingsdaten zu großer Hypothesenraum (mehrere Hypothesen gleichermaßen gut)
- Komplexitätsproblem: Durch Komplexität kann Lernverfahren keine optimale Lösung innerhalb des Hypothesenraums garantieren -> zu rechenintensiv. (Bei speziellen Verfahren oder Heuristiken Gefahr einer suboptimalen Lösung)
- Repräsentationsproblem: Hypothesenraum enthält keine ausreichend guten Approximationen der Zielfunktion/Konzept (gewünschter Approximationsgrad nicht lieferbar)
Fehler
- Man versucht den Fehler der Hypothese mit
E(h)zu schätzen, da nicht berechenbar. - Fehler lässt sich aus Vergleich der Hypothese mit tatsächlichen Wert bestimmen
- Allgemein nicht berechnenbar -> Wahrscheinlichkeitsverteilung nicht bekannt, echter Zustand nicht bekannt aber schätzbar.
Fehlerdefinition

P(x,y): Wahrscheinlichkeitsverteilung des zu lernenden Konzepts
Fehlermaßfunktion

- Distanz
l - Anzahl Missklassifikation (einfach, aber nicht sehr gut)
- Abs. Fehler
- Quad. Fehler
- Probabilistisch
Realer & Empirischer Fehler
- Realer Fehler (über alle real vorkommenden Daten) sind nicht berechenbar -> gute Schätzung nötig
- Formel distanzbasierte Fehlemaßfunktion (s.o.)
- Empirische Fehler auf Datenmenge D
E_D(h)bestimmt (möglichst nahe an realen Fehler) - Lerndaten -> Lernfehler
- Verifikationsdaten -> Verifikationsfehler
- Testdaten -> Generalisierungsfehler (Da ja die Generalisierbarkeit mit den Testdaten getestet wird)
Fehlerminimierung

- Iterative Fehlerminimierung des Fehlers durch Gradientenabstieg auf der Fehlerfunktion
- Start an beliebigen Punkt
- Gradient wird bestimmt
- Iterative Anpassung von
α(Achtungα != a) - α wird mit negativer Änderungrate verschoben
- Nicht ganz korrekt, nur empirischer Fehler dargestellt aber nicht der reale Fehler (empirischer Fehler stehlt nur einen Ausschnitt dar). Stimmt aber meistens hinreichend gut.
- Nach Vapnik wird dadurch nur der erste Teil der SRM minimiert!
- Realität oft problematisch: Mehre lokale Minima möglich
Overfitting
- Tendenz der Maschine sich beim Lernen auf die Lernbeispiele zu spezialisieren (Auswendig lernen)
- Lernfehler fällt, Testfehler steigt, Generalisierungsfähigkeit fällt

- Lernprozess muss angepasst werden wenn keine repräsentativen Daten vorliegen
- Bildet Hypothesenraum überhaupt Zielkonzept ab?
Modellgüte – Validierung
- Wenig komplexes Modell -> Repräsentationsproblem, da wenig Parameter
- Komplexes Modell, da viele Parameter
Validierung
Trick der statistischen Auswertung auf verschiedenen Modellen auch mit relativ wenig Lerndaten evaluieren
cross-validation
- Teile Daten wiederholt in Lern/Validierungsdaten (werden zufällig gezogen aus Ursprungsdatenmenge)
- Bestimme darauf versch. Hypothesen
- Berechne Generalisierung
- Wiederholung
- -> Damit recht gute Aussage darüber wie gut ein Modell ist (Güte/Varianz)
n-fold cross-validation:
- Zerlege die Mege der Lerndaten in n Mengen
- Trainiere jeweils auf n-1 Mengen, teste auf einer Menge
- Wiederhole
leave one out (Spezialfall):
- Jeweils ein Beispiel für das Lernen weggelassen
- Addiere Fehler für weggelassene Beispiele
- Wiederhole
Bootstrap (Ensemble Verfahren)
- Dient nur zur Evaluation von Modellen baut kein neues (besseres) Modell
- Mit einfachen Verfahren/Modellen komplexe Entscheidungen treffen durch Kombination
- Anekdotischer Hintergrund: Paradoxon von Münchausen (am Schopf aus dem Sumpf ziehen)
- Lernen
- Ziehe zufällig mit Zurücklegen aus Daten
Djeweilsk = |D|BeispielemMal - Bestimme jeweils Modell-Parameter
- Bestimme Mittelwert, Varianz der Parameter des Modells
- -> Analyse der Güte/Stabilität
- -> mit weiteren Ansätzen höhere Güte des Modells (z.Bsp. Bagging)
- -> Ensemble von Modellen
Bagging (Bootstrap aggregation)
- Bootstrapping
- Verwende mehrere Modelle
- Kombiniere die Modelle, z.B. gewichtete Summe
- -> Höhere Güte, Stabiltätserhöhung
- -> Aussage über Stabilität (Große Modellunterschiede = unstabil)
Boosting
Dunterteilen inD_1,D_2,D_3- Wähle
D_1und bestimmeM_1 - Wähle
D_2ausDsodass 50% durchM_1korrekt geschätzt werden und erstelle damitM_2 - Wähle
D_3ausDsodass sie gegensätzlich zuM_1,M_2sind und bestimmeM_3 - Kombiniere Modelle zu
M = M_1, wennM_1 = M_2sonstM_3 - Eine Art von Voting
- Vorgänger von AdaBoost
AdaBoost (Adaptive Boosting)
Vergleich zu Boosting
- Generelles Verfahren um Daten aufzuteilen und einfache Modelle zu Generieren
- Lerndaten werden einzeln gewichtet gemäß des letzten Klassifikators
Aufbau
- Lernmenge
DmitnBeispielen - Gewichtung (Anfangs gleich gewichtet) der Lerndaten gemäß Klassifikationsergebnis des zuletzt generierten Klassifikators
- Verringerung des Gewichts von korrekt klassifizierten Beispielen
- Erhöhung des Gewichts von falsch klassifizierten Beispielen
- Mit neuer Lernmenge mit Lernverfahren nächsten Klassifikator bestimmen
- Klassifikatoren 1,..,k am Ende Mehrheitsentscheidung
- Mehrere schlechte Klassifizierer werden kombiniert
- Missklassifikationen vom vorherigen Klassifizieren werden durch nachfolgende verbessert/angesprochen
- Solange die einzelnen Klassifizierer besser sind als Raten wird das finale Modell durch AdaBoost verbessert
- Nicht so anfällig gegenüber Rauschen und Outliers
Algorithmus

- α klein wenn Fehler groß
- α für Gewichtung der Lernbeispiele
- je größer der Fehler desto größer die Gewichtung für den nächsten Klassifikator
Viola Jones
- Echtzeit Gesichtererkennung
- Ist da ein Gesicht? Ja/Nein
- Merkmalsbasiert (Haar-Filter): Summe der Pixel im weißen – Summe der Pixel im schwarzen Bereich
- Sehr ineffizient wenn man alle Haar-Filter auf jeden zu untersuchenden Bereich anwendet.
Kaskadiertes AdaBoost-Verfahren
- Kaskade von einfachen Klassifikatoren
- Jeder Kaskade versucht möglicht viele Fehler rausfiltern
- Rausfiltern von möglich positiven Teilmengen
- Pro Kaskade immer mehr Filter
- Jeder Klassifikator besteht wiederum aus Menge von Haar-Filter
- AdaBoost für jeden Klassifikator
- Ensemble von linearen Entscheidungen
- Am Schluss nur noch (hoffentlich) richtig erkannte Daten
- Erkennungsrate = Alle Positiv aber auch falsch-positiv-Daten enthalten
PAC Probably Approximate Correct
- Was kann man über das Lernen aussagen?
- Gegeben
- Menge
Xvon Instanzen der Längen - Konzept
C - Hypothesenraum
H - Lerndatenmenge
D
Kann in Hypothesenraum H eine Hypothese h gefunden werden die Instanzen aus X auf C richtig abbildet
- Völlig aussichtslos ein korrektes und vollständiges Lernverfahren zu fördern. -> Nein, aber eine Probably Approximate Correct Lernen.
- -> Approximation statt Identifikation
- PAC ist eine Abschwächung, Begriffsklasse
Cist PAC-lernbar wenn: - Hypothese hat Fehler
emit0 < ε < 1/2(approximate correct) - Wahrscheinlichkeit für ihre Auffindbarkeit
1-δmit0 < δ < 1/2(probably) - Lösbarkeit in polynomieller Zeit abh. von
1/ε,1/δ,n - Mit Speicheraufwand abh. von
C
Stichprobenkomplexität

Anzahl der benötigten Lerndaten hängt ab von
- je größer die gewünschte Sicherheit
- je kleiner der zulässige Fehler
- je größer der Hypothesenraum
Desto mehr Daten werden benötigt.
- Leider kann man das bei den meisten Lernmaschinen nicht so einfach bestimmen
Vapnik-Chervonenkis (VC) Dimension (für Klassifikation)
- Maß für die Kapazität von lernenden Maschinen
- C ist PAC-lernbar gdw. VC Dimension endlich
- Maximale Anzahl von Datenpunkten die von
H_α(Hypothese) beliebig separiert werden können (Hyperebenenbeispiel) R^n = n+1

Abschätzung Stichprobenkomplexität
- Bessere Abschätzung der Stichprobenkomplexität

- Statt Kardinalität die VC-Dimension
- Problem VC Dimension ist nicht immer bestimmbar für jede Lernmaschine
- Bei einigen Neuronalen Netzen zum Beispiel
VC-Dimension und Kapazität
- Je höher die VC-Dimension desto höher die Kapazität einer Lernmaschine
- Aber nicht je höher desto besser!
Abschätzung des Testfehlers
(Fragestellung welche VC Dimension hat eine optimale Lernmaschine?)
- Mit W!
1-η (eta)gilt:

- Lernerfolg hängt von
- Kapazität der lernenden Maschine: so gering wie nötig (
VC(h_α)) - Optimierungsmethode: so gut wie möglich (
E_emp(h_α)so klein wie möglich) - Lernbeispiele: repräsentativ, so viele wie möglich (
N)
-> Einfachste Erklärung ist die beste (Rasiermesser-Prinzip von Occam)
Schwierig berechenbar
Structural Risk Minimization
- Ziel: Minimiere Summe nicht einzelne Summanden!

- Empirische Fehler minimieren, Lernmaschine fest, Trainingsdaten konstant
- Realer Fehler wird bis zu einem gewissen Punkt minimiert (Overfittig ab einem gewissen Grad)
VC(h_α)variabel, damit Kapazität der Lernmaschine variabel, Trainingsdaten konstant- confidence term steigt mit steigender VC-Dimension an
- Irgendwann ist die Lernmaschine zu komplex um Konzept richtig zu approximieren
- Korrektes Lernen genau der Punkt an dem die Summe der beiden minimal ist (Optimum)

Idee hinter Lösung
- Strukturierung der Lernmaschine (Hypothesenraum) bestimmen
- Steigende Kapazität der Lernmaschine (VC-Dim steigt)
- Aber auch nicht einfach bestimmbar (analytisch)
- Nicht für alle Lernmaschinen realisierbar
Frage wie kann man für eine Lernmaschine eine gute SRM hinbekommen?
- Neuronale Netze: SRM via Cascade Correlation (MLNN) und DDA (RBF-Netze)
- SVMs machen SRM direkt intern ohne sie explizit zu bestimmen

- Allgemein anerkanntes korrektes Lernen
Neuronale Netze
(Zöllner)
Vergleich Gehirn vs serieller Rechner
Einsatzfelder
Perzeptron

Grundidee
- Anlehnung an das Funktionsprinzip der natürlichen Wahrnehmung
- Reaktion im Tierbereich
- Kann nur lineare Trennfkt repräsentieren
- Limitiert: XOR!
Aufbau
- Eingabevektor
x - Gewichtsvektor
w - Target (Soll-Ausgabe)
t - Output (Ist-Ausgabe)
o
Bias-Trick: Schwellwert t in Input und mit x_0 = 1 und w_0 = - t
Lernverfahren
- Lernen = Anpassen der Gewichte
- Gesucht wird die beste Trennebene
Geometrische Interpretation
- Daten werden in Positive und Negative unterteilt
- Dimension wird um
x_0erweitert - Trennhyperebene (R²: Gerade)
- Gewichte definieren diese Ebene (Normale)
- Gewichtete Summe = Entscheidung -> Skalarprodukt
Lernalgorithmus
- Algorithmus:
- Start
- Lerndatenmenge (Positive + Negative)
w(0)zufälligt=0- Testen
- Punkt x in P&N zufällig
- Falls x in P und
w(t)*x > 0-> Testen - Falls x in P und
w(t)*x <= 0-> Addieren - Falls x in N und
w(t)*x < 0-> Testen - Falls x in N und
w(t)*x >= 0-> Subtrahieren - Addieren
- Setze
w(t+1) = w(t) + x t++, -> Testen- Subtrahieren
- Setze
w(t+1) = w(t) - x t++, -> Testen-
Probleme
- |w| >> |x| -> sehr langsame Anpassung an optimale Trennebene
- Lösung: Normierung
- Fast anti-parallele Vektoren -> springt immer hin und her
- Lösung: Deltaregel (allgemein Gradientenabstiegsverfahren)

Gradientenabstiegsverfahren – Fehlerfunktion
- Muss ableitbar sein!
- Fehlerfunktion Vergleich Soll/Ist-Wert
Kernelmethoden / Kerneltrick
- Transformation in höherdimensionalen Raum der Eingangsdaten
- Problem wird lineal trennbar -> Perzeptron verwendbar!

- φ ist hier die Transformation von R_1 in R_2
Kernel Perceptron
- Lineare Trennung im transformierten Raum führt zu komplexer Trennung im Ursprungsraum

Multi Layer Feedforward Neural Network (MLNN)

Aufbau MLNN
- Mehrschichtiges Neueronales Netz aus Neuronen bestehend
- Gewichtete Verbindungen zwischen Schichten
- Backpropagation Lernalgorithmus
- Neu: Aktivierungsfunktion
- Nichtlineare Aktivierungsfunktion (ableitbar, wichtig für BP-Algo!)
- Sigmoid
- tanh
Backpropagation Algorithmus
Ziel: Gesamtfehler auf Neuronen des Netzes aufteilen (Gewichtsbelegung anpassen entsprechend Fehleranteil)
Radial Basis Function (RBF) Netze
- Vorwärtsgerichtetes, 3-Layer Netz (1 hidden Layer)
- Neuronen der hidden layer lokale rezeptive Felder (mehrdimensional)
- Aktivierung gemäß radialer Basisfunktion (Gauss Funktion mit Zentrum
µund Reichweiteomega - Aktivierung (entsprechend oft Gauß-Glocken gewichtet)
- Auch unsysmetrische Gaußfunktionen -> Rezeptive Felder möglich
- BP-Algo immer noch möglich
TODO Formeln
Aufbau
http://www.neurocomputing.de/RBF/RBF.html
Beispiel

Probleme
- Hoher Rechenaufwand durch nicht-lineare Funktionen
- lokale Minima (mehrere)
- Reichweite kann sher groß werden -> keine lokalen Fehler
Generelle Probleme
- Fehlerflächen
- a) Vorkommen lokaler Minima (werden als Ergebnis angenommen durch Konvergierungsalgorithmus)
- b) Steigung der Fehlerfläche (Steigung mimimal -> konvergiert sehr langsam)
- c) Ausprägung der lokalen Minima (Anspassung führt zum Sprung zurück und iteriert immer weiter)
- d) Lernrate (man kann Mimimum überspringen wenn Lernrate zu hoch ist)

Optimierung des Gradientenabstiegs
- Momentum Term:
- Nicht nur aktuellen Gradienten wird betrachtet sondern auch letzte Gewichtsanpassung (wird gewichtet)
- „Schwung wird mitgenommen“
- Hilft bei Plateau-Fehlerfläche und Zirkulieren
- Normierung der Schrittweite:
- Nicht Betrag des Gradienten sondern Vorzeichen
- Positiv: Nicht abh. von größe des Gradienten
- Negativ: Nicht adaptiv an aktuell benötigte Schrittweite (Plateau: groß, d) klein)
- Lernratenanpassung (RPROP)
RPROP (Resilient Propagation)
- Individuelle Lernrate mittels Gradientenvergleich
- Optimierung von BP-Algorithmus
- Adaptiver Ansatz
- Anpassung der Lernrate abhängig vom Gradientenvergleich
- Wenn Gradient des letzten Schritts in gleich Richtung Zeit wird Schrittrate größer
- Sonst kleiner
- -> Beschleunigung auf flachem Plateau, langsam anpassen im Mimimum
Probleme / Optimierung
- Unterschiedliche Kapazitäten von Neuronalen Netzen
- Perzeptron: Lineare Trennebene
- MLNN: können mehr
- Stellschraube: Organisation des Neuronalen Netzes
- 3 Layer Netz:
- Boolsche Funktion
- kontinuierliche beschränkte Funktion
- 4 Layer Netz:
- beliebige Funktion mit beliebiger Genauigkeit
-> Schon geringe Tiefe ist ausreichend. Topologie spielt eine ausschlaggebende Rolle
- Klassifikation eher SVM, Random Forest Trees
- Regressionsaufgaben eher Gaußschen Netze
Verbesserung der Generalisierung von MLNN
- Kapazität = Generalisierbarkeit
- VC Dim. nicht trivial analytisch bestimmbar
- Konstruktive Ansätze (DDA, Cascade Correlation), kleines Netz wird solange erweitert bis es die Daten lernen kann
- Destruktive Ansätze (z. Bsp. Optimal Brain Damage: Lernen + löschen von Verbindungen), großes Netz wird verkleinert und so daran gehindert die Daten auswendig zu lernen.
Cascade Correlation
- Normales 2 Layer NN
- Algorithmus (Iterativ wiederholen bis max. Anzahl Neuronen oder Fehlerschranke unterschritten)
- Trainiere Netz
- Wenn Gesamtfehler
E(w)> Fehlerschranke - Füge Neuron ein („Kandidat-Neuron“)
- hidden, vor Ausgabeschicht
- vollständig verbunden (mit Eingabe- und Ausgabeschicht)
- Gewicht zu anderen vorher eingefügten Neuronen mit z. Bsp
-1als Gewicht - Trainiere neues Neuron (einmalig)
- Trainiere Netz
<p></p>

- Fahlman: Komplex
* Hohe Ausgabe des Neurons wenn der Fehler des Gesamtnetz hoch ist
* (Ausgabe – Ausgabemittelwert) * (Fehler – Fehlermittelwert) maximieren (Lösen via Gradientenabstieg)
* Gewicht entsprechend anpassen
2. Duda & Hart: Vereinfachte Version
* Prinzipiell wie Fahlmann nur einfacher
* Verbindung zwischen neuen Neuronen mit -1 als Gewicht setzen
* Führt zu maximal unterschiedliche Ausprägung
* Immer dann wenn man in Neuron A kleine Aktivierung hatte hat man in Neuron B eine hohe Aktivierung
-> Bisherige Problemfälle des Netztes werden adressiert.
<p></p>
* Schnell, immer nur ein Neuron muss zusätzlich gelernt werden
* Inkrementelles, konstruktives Lernen
* Kapazität kann iterativ erweitert werden.
Dynamic Decay Adjustment (DDA)
- Konstruktiver Ansatz
- Basiert auf RBF Topologie
- Klasse A/B Neuronen
- Zwei Schwellwerte
- Beispiel: Trainieren von Laufverhalten von Laufmaschinen
Einsatz von MLNN
- Was kann man in einem NN abbilden?
- Subsymbolische Representation von Ein und Ausgabe
- Auswahl von
- Trainingsdaten
- Lernverfahren
- Topologien
- Parametereinstellung
Vergleich Sigmoid-MLNN und RBF-NN
- Sigmoid MLNN: Verteilt (global)
- Änderungen wirken sich global aus
- Generalisierung gut
- RBF NN
- Änderungen nur lokal
- Generalisierung schlechter
- Iterativeres Lernverfahren
- Braucht aber extrem repräsentative Daten
Initialisierung der Gewichte
- Wichtige Rolle
- Gewichte müssen verschieden sein sonst funktionsgleiche Neuronen
- -> Möglichst kleine, gleichverteilte Gewichte
Anpassen der Gewichte
- Patternlearning
- BP direkt nach jedem Lernbeispiel
- schneller, kein echter Gradientenabstieg
- Aber gute Approximation
- Nachteil: Außerreiser bringen Netz eher in suboptimale Form
- Epochlearning
- Mittelung der Gewichtsänderung über alle Beispiele
- Anpassung nachdem alle Beispiele propagiert wurden
- „echter“ Gradientenabstieg
- nicht anfällig für Ausreißer / falsche Lerndaten
Entscheidungstheorie / Entscheidungsbäume
Allgemein
- Jeder Knoten repräsentiert einen Attributtest
- Jeder Zeig entspricht einem bestimmten Attributwert
- Jedes Blatt entspricht einer Klassifikation
- Disjunktion von Konjunktionen von Bedingungen an die Attributwerte einer Instanz
- Diskrete Werte kann man besser verarbeiten mit Entscheidungsbäumen (Realwertige Werte _Regressionsbäme)
Eignung
- Instanzen lassen sich als Attribut-Wert Paare beschreiben
- Zielfunktion besitzt diskrete Ausgabewerte
- Disjunkte Hypothesen
- Verrauschte bzw. Fehler-behaftete Daten
ID3
- Nicht-inkremenntelles Verfahren
- Suche im Hypothesenraum Simple-to-Complex (hill climbing) Algorithmus
- Hypothesenraum ist vollständig -> Zielfunktion ist enthalten
- Nur eine Hypothese wird vorgehalten
- keine gezielte Abfrage von neuen Instanten zur Auswahl unter verbliebenen Hypothesen möglich
- Kein Backtracking:
- Lokale Minima können gefunden werden. (Wie bei allen climbing Algorithmen)
- Nicht-inkrementelle, statistisch motivierte Suche:
- Weniger anfällig gegenüber Fehlern in den Trainingsdaten
Top down Aufbau des Entscheidungsbaums
- A <- Das beste Entscheidungsattribut für den nächsten Knoten (beste = höchste Entropie)
* Weise A als Entscheidungsattribut für den nächsten Knoten
* Füge für jeden möglichen Wert von A einen Nachfolgeknoten ein.
* Verteile die Trainingsdaten gemäß ihrer Attributwerte auf die Nachfolgeknoten.
* Terminiere wenn die Trainingsdaten perfekt klassifiziert
werden, sonst iteriere über die Nachfolgeknoten.
Entropie
- Maß der Homogenität der Trainingsdaten
- Beispiel Münzwurf mit gezinkter Münze = 0, bei normaler Münze am höchsten
- Anzahl der Bits die ich brauche um ein Problem/Lösung zu kodieren (Shannon)

Informationsgewinn
Gewinn(S, A)= Erwartete Reduzierung der Entropie durch die Einsortierung über Attribut A

Bias
- Induktiver Bias: Präferenz für kleine EB und solche, die Attribute mit hohem Informationsgewinn nahe der Wurzel besitzen.
- Präferenzbias
- Restriktionsbias
Occam’s Razor
Overfitting
Vermeidung von Overfitting
- Frühzeitiges Stoppen des Baumwachstums
- Kriterium für optimale Baumgröße
- Sepearte Testdatenmenge -> Klassifikation anschauen -> optimale Größe bestimmen
- Statistischer Test auf Trainingsdaten (x²-Test)
- Maß für die Kodierungskomplexität der Trainingsbeispiele und des Entscheidungsbaums (Prinzip der minimalen Beschreibungslänge) -> Shannon
- Nachträglichen „Pruning“ des Baumes
- Reduced Error Pruning
- Teile die Daten in Trainings- und Testdaten
- Führe Pruning durch solange es sich nicht negativ auswirkt (Evaluation der Auswirkungen, Entfernen des Knotens der die Klassifikationsrate am meisten erhöht.)
- Greedy Ansatz -> Liefert den kleinsten Baum der die Daten korrekt klassifiziert.
- Problem: Bei wenigen Daten erhöht das Aufteilen der Daten die Fehleranfälligkeit noch weiter.
Kontinuierliche Attributwerte
- Definition von Schwellwert um Klasseneinteilung zu erhalten
- Problem: Wie definiere ich einen optimalen Schwellwert?
- Sortierung der Beispiele gemäß ihrer Werte
- Optimaler Schwellwert liegt in der Mitte zwischen zwei benachbarten Beispielen mit unterschiedlichen Klassenzugehörigkeiten
Attribut mit vielen Werten
- Extrem viele unterschiedliche Klassen in den Daten
- Auswahl von Attributen die weniger „splitten“
- Attribute mit größerem
Gewinn(S,A)werden bevorzugt

Unbekannte Attributwerte
- Beispiel: Sensor geht kaputt -> fehlende Attributwerte
- Lösung: Sortiere Beispiele wie gewohnt in den EB ein und
- weise den fehlerhaften den häufigsten Attributwert der Beispiele diesem Knoten zu (gesamte Messdatenmenge)
- weise den fehlerhaften den häufigsten Attributwert der Beispiele der zugehörigen Klasse zu (auf Klasse bezogen mit positiven bzw. negativen Klasse als Endergebnis)
- weise jedem Wert die Wahrscheinlichkeit zu und verteile das Beispiel gemäß anteilig auf die Nachfolger
- Klassifikation analog
Attribute mit Kosten
- Beispiel mit medizinischer Diagnose
- Bestrafungsfunktion Kosten werden mit einbezogen in den Gewinn

Windowing
- Interessant bei großen Datenmengen
- Algorithmus:
- Wähle zufällige Untermenge („Window“)
- Bestimme EB für Window
- Klassifiziere restl. Daten mit Window-EB
- Falls nicht alle Daten korrekt klassifiziert füge einen Teil der falsch klassifizierten zum Window hinzu und erstelle EB erneut
C4.5
- Nicht-inkremenntelles Verfahren
- Verbesserung des ID3 durch generalisierte Regeln (Pruning)
- Dann mit verrauschten und fehlerhaften Daten umgehen
- Wandelt den Baum in if-then-Regeln um, danach Pruning
- Kommerzielles System
Rule Post-Pruning
- Baum aufbauen (Overfitting erlaubt)
* Umwandeln in if-then Regeln
* „Prune“ (Generalisiere) die Regeln so lange sich ihre Vorhersagegenauigkeit nicht verschlechtert (durch Entfernen von Vorbedingungen).
* Sortiere alle Regeln nach ihrer Klassifikationsgüte und verwende sie in dieser Reihenfolge.
Zusammenfassung
- Regelgüte: Standardabweichung bestimmen, untere Schranke Konvidenzintervall = Regelgüte
- Statistisch nicht einwandfrei aber Praxistauglich
- Proprietär wenig bekannt
- Vorteile
- Unterscheidung zw. verschiedenen Kontexten in denen ein Entscheidungsknoten benutzt wird
- Keine Unterscheidung zw. Attributen näher an Wurzel und solchen näher an Blättern
- Lesbarkeit
ID5R
- Inkrementelles Verfahren
- Ergebnis ist äquivalent zu ID3 Baum
- Viele Zähler im Baum enthalten
Repästentation der EB
- Messdatenmenge ist im Entscheidungsbaum enthalten
- Antwortknoten:
- Werden in Entscheidungsknoten umgewandelt wenn eine andere Klasse gezogen wird
- Entscheidungsknoten:
- Algorithmus:
- A
* B
Random Forests
- Mehrere Einscheidungsbäume (10-1000 je nach Problemgröße)
- viele kleine einfache,
- unkorrelierte Bäume
- Zufällige Wahl von Attributen
- Jeder Baum sollte für sich ein guter Klassifikator sein
- Entscheidung basierend auf Mehrheitsentscheid
- Training und Evaluation sind parallelisierbar, da getrennt voneinander abarbeitbar.
- Effizient bei großen Datenmengen
- Overfitting wird ignoriert weil „die Masse machts“
- Kein Pruning mehr
- Randomisierungsmöglichkeiten:
- Bootstrapping
- n Beispiele mit zurücklegen aus n Trainingsdaten -> 63% der Größe der verglichen mit Ursprungsdatensatz
- Über Attributmenge Teilmenge für Bäume definieren
- „right kind of randomness“
Instanzbasiertes Lernen
Allgemeines
- Lazy Learning (Rechenaufwand nicht während dem Lernen sondern während der Klassifikation -> teuer)
- Lernen eigentlich nur Abspeichern der Trainingsdaten
- Lokale Approximation der Zielfunktion, damit unterschiedliche Hypothesen
- Komplexere symbolische Repräsentation für Instanzen
- Komplexere Zeilfunktion möglich
- Information aus Trainingsbeispielen geht nicht verloren
- Hypothesenraum nicht so eingeschränkt als wie bei „Fleißigen“ Lern-Algos
- Geneardliesierungsentscheiden erst bei Suchanfrage
- Neue Instanzen werden analog zu „ähnlichen“ Klassifiziert
- Was ist ähnlich?
- Problem irrelevanter Eigenschaften
- Müssen vorher bekannt sein
k-Nearest-Neighbor (k-NN)
- Subsymbplisch, nicht inkrementell
- N-Dimensionaler Instanzvektor
- Nachbarschaftsbeziehung definiert durch Distanzfunktion
- Euklidische Distanz
- TODO Grafik Formel
- Konzeptlernen:
f: R^n -> V, V =endliche Menge - Trainingsalgorithmus: Hinzufügen der Traininsbeispiele in Liste
- Klassifikationsalgorithmus: Bestimmen der Klasse anhand der k nächsten Nachbarn
- Tradeoff:
- k zu groß: Einfluss von weit entfernten Instanzen
- k zu klein: Descission-Boundary (Voronoi-Diagramm)
Normalisierung von Dimensionen
- Verzerrung bei stark ungleichen Eingabedimensionen (Fehlgewichtung einer Dimension mit kleinerem Wertebereich)
TODO Grafik
Abstandgewichtung
- Man kann noch nähere Nachbarn stärker Gewichten, wie weiter entfernte
- Distanzbasierte Gewichtung
TODO Formel
Bewertung k-NN
- Induktiver Bias: Klassifikation anhand benachbarter Instanzen
- Vorteile
- Robust bei verrauschten Daten (besonders gut wenn Gewichtung genutzt wird)
- Nachteile
- Distanzmaß basiert auf allen Attributen
- Evtl nur Untermenge relevant (->PCA)
- Curse of dimensionality
- Speicherorganisation
- Hauptzeitaufwand während Klassifikation
Case-based Reasoning (CBR)
- Allgemeines (abstraktes) Framework
- Kein direkt anwendbarer Algorithmus
- Analoges Schließen (Beispiel: Sonnensystem und bohrsches Atommodell)
- Basiert auf Erinnerung, Wiederverwendung alter Fälle
- Adaption von vorhandenen Lösungsansätzen
- Menschenähnliches Vorgehen
Definition Fall
- Kognitionswissenschaften: Abstraktionen von Ereignissen begrenzt in Zeit und Raum
- Technische CBR Sichtweise: Fall bereits real aufgetreten + bei der Bearbeitung gemachten Erfahrungen
- Mindestens:
- Problembeschreibung
- Lösungs(-versuch)
- Ergebnis
- Zusätzlich:
- Erklärung für Ergebnis
- Lösungsmethode
- Pointer auf andere Fälle
- Güteinformation
CBR Zyklus
TODO cbrZyklus Bild
- Auffinden (Retrieve)
* Ähnlichkeitsmaß
* Organisation der Fallbasis
* Effizientes Auffinden von Fällen -> Indizes
* Manuell
* Check-Liste
* Differenzbasiert
* Kombination beider Methoden
2. Wiederverwendung (Reuse)
* Lösungsadaption
3. Anpassen/Überarbeiten (Revise)
* Evaluierung der Lösung
* Verbesserung bzw. Reparieren der Lösung
* (Potentiell Iterativ!)
4. Zurückbehalten (Retain)
* Bewahrung der gemachten Erfahrungen
Bewertung
Vorteile
- Konzept einfach, trotzdem komplexe Entscheidungsgrenzen möglich
- Relativ wenig Information notwendig (Geringer Beispielumfang notwendig)
- Analog zu menschlichen Problemlösen
- Lernen ist einfach („one-shot learning“)
- Günstig für mit Regeln schlecht erfassbare Probleme
Nachteile
- Gedächtniskosten
- Klassifikation kann lange dauern (Repräsentationsabh.)
- Problematisch bei komplexen Representationen
- Problem: Irrelevante Eingeschaften (Müssen vorher bekannt sein)
Bayes Lernen
- Gold-Standard für Beurteilung von (nicht-stat.) Lernverfahren
- Praktische Probleme:
- Initiales Wissen über W! notwendig
- Nicht-inkrementelles Verfahren (gibt auch inkremmentelle)
- Es werden seehr viele Trainingsdaten benötigt um Wahrscheinlichkeiten zu bestimmen
- Subsymbolisch (Arbeiten mit W!)
Statistische Lernverfahren
- Kombinieren vorhandenes Wissen (a priori W!) mit beobachteten Daten
- Hypothesen können mit einer W! angegeben werden (vorher nur 0 oder 1) -> Gütemaß!
- Jedes Beispiel kann Glaubwürdigkeit einer Hypothese verändern
- z. Bsp. besser einsetzbar bei verrauschten Daten
- -> Robuster
- Mehrere Hyppothesen miteinander kombinierbar -> besser Ergebnisse
Theorem von Bayes
Maximum a posteriori (MAP) Hypothese
P(D) ist unanhängig von der Hypothese damit nicht weiter relevant
Maximum Likelihood (ML) Hypothese
- Da man eine Gleichverteilung der Hypothesen annehmen muss (kein Wissen darüber), kann man P(h) weglassen
- -> ist nur ein Skalierungsfaktor der bei allen Hypothesen gleich ist
- Ohne Vorwissen ist MAP = ML
Brute Force Lernen von MAP-Hypothesen
- Sehr teuer bis ummöglich
Konzeptlernen
- Versionsraum VS (Enthält nur konsistente Hypothesen mit Testdaten)
- Induktiver Bias: Menge aller Annahmen die getroffen werden müssen um die Ergebnisse eines induktiven Lerners dekduktiv abzuleiten
- Anforderungen festgestellt die man braucht um Konzeptlernen durchführen zu können
- Annahmen…
- Ergebnis
- Was würde passieren wenn die Trainingsdaten nicht nicht-verrauscht sind?
- Verteilung kann auch Werte annehmen die nicht auf 0 oder konst. Wert fallen
Lernen einer reell-wertigen Funktion
- Regression statt Konzept
- Grundannahme lineare Funktion
Prinzip der minimalen Beschreibungslänge (MDL-Hypothese)
- Occam‘s Razor: Bevorzuge die einfachste Hypothese, die mit den Trainingsdaten übereinstimmt.
Klassifikation neuer Instanzen
- Bisher: Hypothese mit höchster aposteriori W!
- nicht MAP-Hypothese!
Optimaler Bayes-Klassifikator
- Kein anderes Klassifikationsverfahren das bei gleichen Vorwissen im Durchschnitt besser abschneidet.
- Aber: Sehr kostenintensiv bei großer Hypothesenanzahl!
Gibbs Algorithmus
Naiver Bayes-Klassifikator
- Annahme der bedingten Unabhängigkeit von Attributen
- Gilt eigentlich aber oft nicht
- Trotzdem gute Werte
- Klappt aber nicht immer
Bayes’sche Netze
- Zwischenstufe zwischen Optimalen und Naiven Bayes-Klassifikator
- Relativiert: Nur noch Untergruppen von Attributen sind bedingt unabhängig
- Basiert auf gewichtetem DAG
Inferenzverfahren
Lernen
Drei Fälle:
1. Struktur bekannt, alle Vars beobachtbar: Naiver Bayes-Klassifikator
2. Struktur bekannt, nur einige Vars beobachtbar: Gradientenanstieg, EM
3. Struktur unbekannt: Heuristische Verfahren
Expectation Maximization (EM) Algorithmus
- HMM ist Spezialfall von Bayesschen Netzen
- Baumwelch-Algo Instanz von EM-Algo
- Liefert nur ein lokales Optimum!
Vorgehensweise für gauß-mixtures
- E (estimination) Schritt
- M (maximum likelihood) Schritt
Allgemeines EM-Problem
- Liefert Erwartungswert von logarithmierter MLverteilung approximieren
Support Vector Machines (SVMs)
(Zöllner)
- Gehören zu den Kernel-Methoden
- Occams Razor principle
- SVMs kommen da sehr nahe heran
- Klassifikations-Gold-Standard
- SRM wird versucht zu erfüllen
Lineare Support Vektor Methode

- Klassifikation, Trennung von zwei Mengen
- Finde beste Trenngerade
- Maximierung des Randes (Marging) <=> Maximierung der Generalisierung
- In der Realität nicht so schön linear
Geometrische Interpretation und Formalisierung
- Trennhyperebene ist nicht von allen Lerndaten abh. nur von nahen Punkten
- α für weit entfernte gegen 0
- Die nahen Punkte nennt man Support Vektoren

Lagrange Methode zur Minimierung
- Lernen = Optimierungsproblem lösen
- Minimierung von Optimierungsproblem mit Randbedingungen
- Gesucht: Sattelpunkte
- Duale Lagrange-Gleichung -> Duales Optimierungsproblem
- Nur noch von Lagrange Multiplikatoren α abhängig
- Einfacher zu lösen
Wird „nur“ angewendet nicht weiter hergeleitet
Support Vektoren
- Nur von einigen Supportvektoren abh.
- Liegen am nächsten zur Trennebene
wist eine Linearkombination weniger Vektorenx(Supportvektoren)w = Summe_i(α_i*y_i*x_i')- Die meisten α = 0 es reichen in 2D schon 3 Punkte
- Damit sehr schnell berechenbar
Nichtlineare Support Vektor Methode
Soft-margin SVM
- Genearlissierte optimimale Hyperebene
- Einfürhung von Slack-Variabeln ξ >= 0 (aber klein)
- Erlaube eine geringe Zahl von Missklassifikationen
- Es dürfen Datenpunkte bis zu einem bestimmten ξ missklassifiziert werden
- Aber es gibt auch Probleme die man nicht so trennen kann
- Anpassung des Minimierungsproblems

- Parameter
C: Regulierungsparameter Cgroß -> wenig MissklassifikationCklein -> maximale Margins- Aussage von
C - (Alle Vektoren
x_imitα_i> 0 = Support Vectoren) α_i < C: Supportvektor liegt am Rand Abstand 1/||w|| (margin vector)α_i = C:ξ_i > 1Fehlklassifikation0 < ξ_i <= 1Richtig, geriner Abstand = margin errorξ_i = 0margin vector
Kernel Trick

- Idee: Transformiere die Daten in einen anderen Raum und versuche es dort zu lösen
- Meistens einen Raum höherer Dimension
- Nicht immer: z. Bsp: Zwei Spiralen in 2D in Polarkoordinaten transformieren (auch 2D)
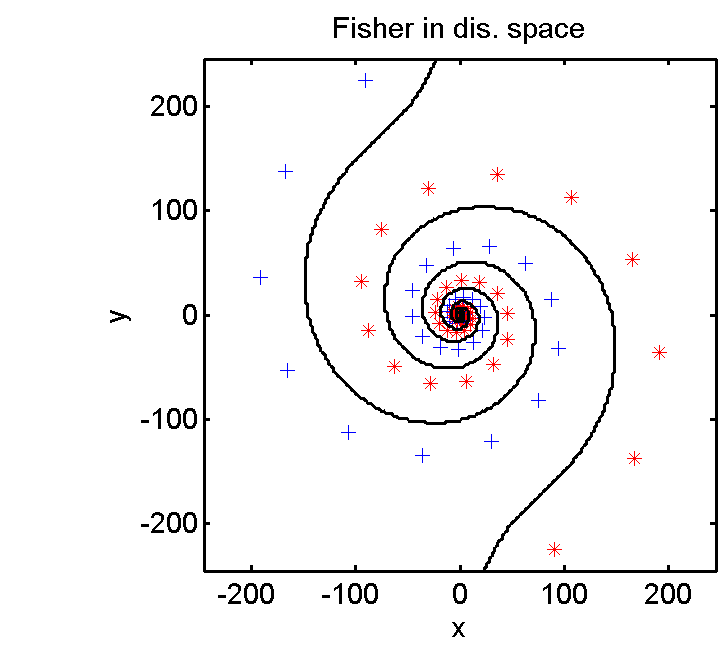
- Bei Klassifikation: Lineare Trennung in diesem Raum
- Aber Rechnen in Hochdim. Raum sehr teuer
- -> Dank Lagrange-Methode ist aber nur das Skalarprodukt, nicht komplette Transformation notwendig
- Es kommt nie φ(x) alleine vor immer irgendwie als Skalarprodukt
- Einzige Form in der die Daten vorkommen ist das Skalarprodukt
Beispiel Monomtransformation:

Kernels
(Skalarprodukte)
TODO Formeln einbauen
Architektur
- Gewisse Ähnlichkeit zu FF-NN mit Sigmoid-Schwellwert (tanh)
- Lernen unterscheidet sich aber deutlich (vorallem bei BP-NNs) -> andere Ergebnisse
- Vor allem weil Support Vektoren für den Rand zuständig sind?!
Version Space für SVM
- Grund warum SVMs die SRM implizit umsetzen
- Dualität zwischen feature space und hypothesis space
- Generell sucht man
wundbdie die Randbedingungen am besten erfüllen - Man kann das Problem auch rum drehen
- Jeder Datenpunkt erzeugt eine Trennebene in Hypothesenraum, die den Hypothesenraum einschränkt.
- Jeder weitere Datenpunkt, der ein Supportvektor ist (also nahe genug an der Grenze zwischen den beiden Klassen liegt) verfeinert den möglichen Hypothesenraum weiter
- Mittelpunkt dieser Hyperkugel ist die optimale Lösung
- VC-Dim. hängt von Radius der Hyperkugel ab
- -> Durch Hinzunahme bzw. Weglassen von (relevanten) Datenpunkten kann der Hypothesenraum/VC-Dim der Lernmaschine beeinflusst werden.
- VC-Dim. h fällt stehtig h <= D²*|w|² (D = Radius der Hyberkugel)
- -> Damit SRM während Lernen implizit!
- -> Kleinste und beste Realisierung für w -> Occamsches Prinzip

Erweiterungen
- reduced – RSVM
- Kleine Anzahl (regulierbar) von Support Vektoren Entscheidung wird anhand der Randregionen gefällt
- Verfahren für multiple Klassifikation
- Kombination von Einzelverfahren
- Jeder gegen jeden
- Einer gegen alle
- Mehrfachzugehöhrigkeit mit verschiedenen Anteilen
- -> Aber nicht wesentlich besser als Abstimmungsverfahren
- Gewichtete SVM
- Klassen werden einseitig mehr oder weniger gewichtet
- So wie Soft-Margin Klassifikation (nur einseitig)
- Dichte Träger Schätzung
- Problem: Es gibt nur eine Art von Daten
- Bereich im Raum wo die Daten sich Clustern
- Suche nach Datenclustern
- -> Trennhyberebene in transformierten Merkmalsraum
- -> Analog zu Klassifikationsproblem (Optimierungsproblem)
- Kernel Perceptron
Vergleich mit NNs
- SVMs liefern immer eindeutige Lösung, was NN nicht leisten können
- NNs nicht so stabil (Reihenfolge der Trainingsdaten, Initialisierung der Gewichte haben bei NNs Einfluss auf das Ergebnis)
Anwendungen
- SVM Regression ist nicht so gut wie Gaußsche Ansätze
- Bei Konzeptlernen besser
-
PCA mit SVM/Kerneltrick
- Semiüberwachtes Lernen
- Aktives Lernen
- Klassifikation von Gesichtern
- Blickrichtung
- Geschlechter
Reinforcement Learning
(Zöllner)
- Wurde extra nicht in die Kategorien eingeordnet
- Spezielle Art des Lernens
- Verstärkendes Lernen mit direktem Feedback
- Bellmann Gleichung heißt eine rekursive Formel?!
Gesetz der Auswirkung
- Biologisch motiviert
- Tierwelt: Reaktionen werden stärker mit einer Situation verknüpft, die einen befriedigenden Zustand begleitet (bei unangeneme Zustände werden die Reaktionen/Situationen schwächer verknüpft)
- Skinner Box (Maus, Käfig, Taste + Licht = Futter, Taste + kein Licht = Stromschlag)
Lernziel
- Ziel: Maximale Bewertung von Aktionssequenz
Markov desicion process (MDP)
- Zustandgetriebener Entscheidungsprozess zur Formalisierung
- Markov-Bedingung: keine Abhängigkeit von der Vergangenheit
- „Autonomer Agent & Umwelt“
a_t= (Aktorik) Einwirken auf die Umwelt durch Aktions_t= (Sensorik) Erfassung (partiell) von Zustand,d(s_t, a_t) = s_{t+1}(Zustandsänderung)- Bewertung von Aktionen
r_t= Bewertung zum Zeitpunkttr(s_t, a_t) = r_t- Ziel: maximale Bewertung (reward)

Anwendungsbeispiele
- Steuerung von Robotern (Post holen)
- Spiele (Schach, Back-Gammon)
- Optimierung und Planung (Fertigungsprozesse, Taxizentrale)
Strategielernen (Policy-learning)
- Gesucht optimale Zielfunktion (target function)
- sodass die akkumulierte Bewertung maximiert wird
- State-Value-Function
- Gewichtung der Bewertung (Diskontierungsfaktor)
0<=γ<=1 - -> um in Zuknft liegende Bewertungen schwächer zu gewichten
0: nur aktuelle Aktionsbewertung ist wichtig (1-step)>0: zukünftige (letzte) Bewertung werden brücksichtigt (n-step)<1: notwenidg für konvergente V Funktion- Ansonsten lange Aktionsfolgen unendlicher revert!
- Ann: absorbierender Terminalzustand, dh.h. alle Aktionen führen konstenfrei wieder in den Zustand, damit Algo terminiert.

Optimale Strategie
- optimale Zielfunktion
- Bekommt man aber leider nicht so einfach hin
- max. akk. Bewertung
- rekursive Definition (als Bellmann Gleichung)
- Problem: Wie erhält man V*(s)?
Simple Temporal Difference Learning 1 (Simple Value Iteration)
- Hartes Ersetzen
- Basis aber sehr langsames Lernen für Praxis nicht anwendbar
Simple Temporal Difference Learning 2
- Bruchteil der Differenz zwischen den beiden Zustandsbewertungen wird hinzugefügt
- Schnellere Konvergenz als Version 1
- Ähnlich zu Update-Funktion bei Neuronalen Netzen
- Nach wie vor Probleme:
- Erwarten in jedem Zustand einen revert r(s,a)-Funktion
- Explizite d(s,a)-Funktion beim Lernen und auch um Policy auszuwerten
- Aktuelle Schätzung durch die Policy bestimmt dadurch sehr langsames Lernen/Konvergenz
Problemdimensionen in RL
- Zielfunktion: ??
- Bewertung: direkt <-> verzögert (z.B. Back-Gammon, erst am Ende der Aktionskette klar ob Aktion x_i sinnvoll war)
- Zustandsübergänge: deterministisch <-> stochastisch/nicht deterministische Prozesse
- Zustand in der Realität nicht vollständig beschreibbar
- Modell (Simulation) des Systems: vorhanden <-> nicht vorhanden
- Zustandsraum und Aktionsraum (bekommt man mit RL aktuell noch nicht in den Griff):
- eindimensional <-> hoch-dimensional
- diskret <-> kontinuierlich
Deterministisches MDP
Q-Funktion (Action-Value Function)
- Motivation: in der Realität gibt es keinen revert/Bewertung direkt durch die Aktion sondern oft erst am Ende einer Aktionskette
- Zustandsübergangsfunktion ist nicht bekannt
- Definiert maximale Bewertung für Zustands-Aktions-Paar
- wenig Wissen über Zustandsübergänge nötig

- Idee Lerne ^Q(s,a) Wähle beste Aktion anhand einer Strategie:

Q-Lernalgorithmus
- ^ heißt Schätzung
- Konvergiert, beweisbar für deterministisches System
- Initialisierung aller Q(s,a) mit 0
- Zufällig über alle Zustände iterieren
- Wähle Aktion a aus
- r = direkte Bewertung
- neuer Zustand s‘
- update
- Hartes Ersetzen gemäß Bellman-Gleichung für Q

- s <- s‘
- Korrektheit und Konvergenz nach n Iterationen falls gilt:
- |r(s,a)|<c
- deterministisches System
- wenn alle Paare (s,a) unendlich oft besucht werden

- Dauert noch länger als V zu schätzen!
Suchstrategien
- Welche Aktion in Zustand s als nächstes gewählt werden könnte? (Besser als Raten)
- -> Exploration und Exploitation
- Probabilistische Modellierung für jede Aktion
- k groß -> Q-Wert wichtiger -> Lokales Lernen
- k klein -> Aktionen werden auch bei kleinen Q gewählt -> Alle Aktionen haben rel. große W! gewählt zu werden -> globales Lernen

Exploration vs Exploitation
- Während dem Lernen anfangs Exploration (globales Lernen) und dann wenn es Pfade gibt diese zu verbessert (lokales Lernen) durch eine Exploitation
- Beste Lösung: Änderung der Suchstrategie von global zu lokal während des Lernprozesses
Optimierung
- Kein hartes Update sondern Fehler bestimmen und gewichtet einfließen lassen
- Abhängigkeiten der Q Werte untereinander zu speichern
- Update von Paar (s,a) führt zu Update aller abh. Paare (s‘,a‘) die zu (s,a) führen
- Ein Schritt passt mehre Werte von Q an
- -> Schnellere Konvergenz
- -> Mehr Speicheraufwand
- Sinnvoll wenn: Aktionen benötigen hohen Zeitaufwand (Robotik)
- Lernen mit adaptiven Modell
- Meisten Lernschritte auf simulierter Umgebung
- Ab und an Update aus Realität (wenig Interaktion)
- Synchronisation, Anpassung des Modells
- -> Schneller als in der Realität
- Bsp. Dynamiksimulation aus Robotik, Spiele (Backgammon)
Repräsentation/Generalisierung
- Problem: Kontinuierlicher Zustandsraum
- Speichern der Q-Werte in Lookup-Tabelle unmöglich
- sehr hohe Anzahl von Lerniterationen nötig
- Kombination von RL mit Methoden höherer Generalisierung
- z. Bsp Neuronale Netze (können gut Generalisieren, d.h. nicht explizit alle Werte in Lookup-Tabelle notwendig kann in NN gespeichert werden)
- Ein Netz für alle Aktionen oder
- pro Aktion ein Netz oder
- direktes Lernen der besten Aktion
- Update-Werte für Q(s,a) sind Lernbeispiele für das Neuronale Netz

Nichtdeterministische MDP
- Folgezustand ist noch zusätzlich von einer gewissen Wahrscheinlichkeit abhängig
- Umdefinition der Bellman-Gleichungen:
- Nicht nur ein revert sondern Erwartungwert über alle möglichen Zustände
- Nicht nur einen Q-Wert sondern das max. der möglichen Folgezuständen

Lernen von Aktionssequenzen
- Unmittelbarer Revert beim Durchführen einer Aktion nicht anwendbar beispielsweise bei Spielen (Backgammon)
- Revert kann erst am Ende einer Sequenz gelernt werden
- Nachfolgende Aktionen können für den schlechten Ausgang verantwortlich sein
Temporal difference learning (TD)
- Die Differenz folgender Schätzungen als Lernsignal für Q(s,a), V(s)
- Vorwärts – Sicht (theoretisch)
- Gewichtete Anpassung an direkt nachfolgender Schätzung (1-step) oder
- Gewichtete Anpassung an n Schritte nachfolgender Schätzung (n-step)
- Aber: Rückwärtige Sicht des TD-Lernen (praktisch)
- Fehlersignale (temporal differences) in den Schätzungen werden nach hinten weitergegeben
Eligibility Traces
- „Verantwortlichkeitsspur“
- Zustände für die Zustandsbewertung -> V-Lernen
- (Zustände/Aktion) für die Q-Wert Bewertung -> Q-Lernen
- e_t(s) nimmt stetig ab außer es wurde der Zustand besucht
- Zählt wie oft ein Zustand/Aktion/Zustand-Aktion-Paar in der Vergangenheit vorkam
- Sie geben an wie Zustand/Aktion/Zustand-Aktion-Paar sie den Wert des jetzigen Zustands beeinflusst

SARSA(λ)-Algorithmus
- Erweiterung des Basisalgorithmus (Q-Lernen?!
- (Bereits angepasst mit weichen Update)
- Sofern es ein Revert gibt
- Fehler bestimmen und
- Eligibility erhöhen
- Für alle (s,a) in der Zustandsfolge durchführen
- Sonst kein Update der Werte
- -> Schnellere Konvergenz

Beispiele
- Optimierung von Systemen
- Fahrstuhlsteuerung, 4 Stück, Minimierung mittlere Wartezeit
- Randbedingungen (Vorwissen) vereinfachen das Lernproblem (Lernraum)
- Trotzdem Zustandsraum groß -> NN -> braucht relativ wenig Lernbeispiele
Hidden-Markov-Modelle (HMM)
Markov Logik Netze (MLN)
Evolutionäre Alogrithmen
(Zöllner)
- Biologisches Evolutionsmodell nach Darwin:
- Selektion = Treibende Kraft der Evolution
- Evolution als Optimierung komplexer, künstlicher Systeme auf Basis von:
- Selektion
- Zufall
- Es handelt sich oft um eine Parallelisierung eines Problems
Nomenklatur
- Individuum: Eine mögliche Hypothese
- Population (und Generation): Menge von Hypothesen
- Erzeugen von Nachkommen: Generierung von neuen Hypothesen
- Rekombination
- Mutation
- Nachfolger: Kind, Nachkomme <- Neue Hypothese
- Fitnessfunktion: Hypothesengüte, zu optimierendes Kriterium, Erfolgt auf Lernbeispielauswertung
- Selektion der Besten: Auswahl der Hypothesen, welche die beste Problemlösung erzeugen
- Welche Hypothese darf Nachfolger erzeugen?
- Welche Hypothese überlebt?
Grundalgorithmus

Repräsentation
- Wissen strukturiert repräsentiert
- Kodierung via k-Alphabet
- (k=2 Binär): Genetische Algorithmen
- Reelle Zahlen: Evolutionäre Strategien
- Programmcode: Genetisches Programmieren
- Wie viel von dieser Strukturinformation soll genutzt werden?
- Gibt keine goldene Regel dafür- Fallabh.
Generierung von Nachkommen
- Exploration
- Erforschung des Hypothesenraumes (globale Suche)
- Je stärker und zufälliger Änderungen sind, um so geringer ist die Wahrscheinlichkeit, bessere Nachkommen zu erzeugen
- Exploitation
- Lokale Optimierung
- Bei lokalen Verbesserungsmethoden ist die Gefahr der lokalen Minima gegeben
- Wird im Laufe der Suche nach den besten Individuen angepasst von Exploration zu Exploitation
Mutation
- hängt von einem Elternteil ab
- Gene werden Mutiert (z.B. Bitinversion)
- Unterschiedliche Mutationsoperatoren möglich
- Zufällige Invertierungen an bestimmten Stellen/Bits
- Herausnehmen und Einfügen an anderer Stelle
- Invertiertes Einfügen einer Teilsequenz
- Es müssen gültige Hypothesen generiert werden
- Oft anwendungsspezifisch
Rekombination
- Zwei Elternteile werden vermischt
- Aber man muss aufpassen valide Hypothesen zu generieren
- Diskrete Rekombination
- Abwechseln aus Elternteilen
- Intermediäre Rekombination (reelle Zahlen)
- Funktionsdefinition
- Crossover Rekombination
- 2 Eltern -> 2 Nachkommen
- Single-point crossover: Durchmischen an einer Stelle
- Two-Point crossover: an zwei Stellen
- Uniform crossover: Abwechselnd
Selektion
- Selektion der Überlebenden Populationsmitglieder
- Selektion der Eltern
- Probleme:
- Genetische Drift:
- Individuen vermehren sich zufällig mehr als andere
- Crowding, Ausreißerproblem:
- „fitte“ Individuen und ähnliche Nachkommen dominieren die Population -> Lokale Minima
- -> Langsame Konvergenz und Vielfaltseinschränkung
- Lösungen
- Verschiedene Populationsmodelle und Selektionsmethoden
- Populationsgröße optimieren
Populationsmodelle
- Aussuchen und kombinieren von Individuen
- Inselmethode: Evolution getrennt (Inseln), manchmal Austausch von Individuen
- Nachbarschaftsmodell (nahe Umgebung): Nur Fitte Nachbarn erzeugen Nachkommen
- Einfache Menge (global): die global Besten entwickeln sich rasch weiter, andere Entwicklungslinien werden unterdrückt
Populationsmitglieder
- Populationsgröße
- Soll sie konstant bleiben (Populationsgröße µ)?
- Wie viele neu erzeugte Nachkommen (Anzahl Nachkommen λ)?
- Wie viele Eltern sollen verwendet werden (Wahrscheinlichkeit der Auswahl von Eltern p)?
- Wie werden diese bestimmt
Mitgliederselektion
- stochastisch ausgewählt -> die besten µ Individuen
- (µ, λ) Strategie: Auswahl nur Nachkommen (bessere Exploration)
- (µ + λ) Strategie: bezieht auch Eltern mit ein (die Besten werden berücksichtigt, Suche nach Eliten -> Exploitation, günstig bei gut berechenbaren Fitnessfunktionen)
Ersetzungsregel für Mitglieder
- Generationsmodus
- Geographische Ersetzung
- Elitist Modus (Bestes Individuum überlebt)
- Daumenregel
- Das beste Viertel der Population sollte drei Viertel der Nachkommen erzeugen
Selektionsmethoden
- Wahrscheinlichkeit p für Auswahl
- Fitness Based Selection: Aber nach einiger Zeit nur noch geringe Fitnessunterschiede
- Ranking Based Selection: Weniger abh. von Betrag von Fitness, besser Anpassbar an Exploration/Exploitation
- Tournament Selection (Turnier)
Evolution
- Wie kombiniere ich jetzt die Individuen?
- Wird bei Neuronalen Netzen angewendet
- Lamarksche Evolution
- Individuen ändern sich nach der Erzeugung (lernen dazu)
- Genotyp wird verändert und vererbt
- Baldwinsche Evolution
- Individuen ändern sich nach der Erzeugung (lernen dazu)
- Nur zur Fitnessbewertung
- Genotyp bleibt unverändert
- Hybride Verfahren
Genetisches Programmieren
- Erzeugung optimierter Programme
- Individuen sind Programme
- Repräsentation durch Bäume
- Rekombination als Austausch von Teilbäumen
- Fitness: Programmtest auf einer Menge von Testdaten
Unüberwachtes Lernen
Grundidee
- Ausnutzen von Ähnlichkeiten in Trainingsdaten, um die Klassen / Ballungen zu erschließen
- Beobachtet eine Folge von Objekten / Ereignissen
- Formt dabei (hierarchische) Konzepte, die seine Erfahrungen zusammenfassen und organisieren
Verfahren
- Klassische Verfahren (subsymbolisch)
- k-means
- Agglomerative Hierachical Clustering
- Begriffliche Ballung (symbolisch)
- Begriffshierachien
- COBWEB
- Lernen durch Entdecken
k-means-Clustering
- subsymbolisch, unüberwacht, nicht-inkrementell
- Klassifiziert eine Datenmenge in eine a-priori vorg. Anzahl von Ballungen
- Definieren eines Mittelpunkts (Vorläufig) für jeden Cluster
- Iterative Anpassung / Verbesserung
- Optimalitätskriterium: Minimierung der Abstände aller Datenpunkte von ihrem Ballungsmittelpunkt
- Minimierung von

Algorithmus
- Platziere
kErsten Datenpunkte (Ballungszetrumsmittelpunkte) - Klassifiziere Datenpunkte nach minimalen Abstand zu den Ballungszentren
- Mittelpunkte werden gemäß den Ballungen verschoben zum neuen Zentrum
Bewertung
- Lösung hängt stark von initialer Belegung ab
- Suboptimale Lösung kann gefunden werden
- Mögliche Lösung: Algo mit unterschiedlichen Startpunkten anstoßen
- Resultate hängen stark von der verwendeten Metrik als Distanzmaß ab
- Curse of Dimensionality
- Resultate hängen von der korrekten Wahl von k ab
- Keine fundierten theoretischen Lösungen
- Ergibt sich
kaus der Domäne? - k<<n -> sonst Overfitting!
Fuzzy-k-means-Clustering
- Beim normalen k-means: jeder Datenpunkt in genau einem Cluster
- Abschwächung: jeder Datenpunkt x_i hat eine abgestufte / „unscharfe“ Zugehörigkeit zu jedem Cluster X_j
Hierarchische Ballungsanalyse
- k-means: kann nur flache Datenbeschreibung
- Ballungen können Sub-Ballungen haben (beliebig tief)
- Iteratives Vereinen von (Sub-)Clustern zu größeren Clustern
- Dendogramm

Agglomerative Hierarchical Clustering
- Erzeugt Dendogramm wenn t = maxdist xi
- O(n3): n mal jeden Cluster mit jedem Vergleichen
- Distanzmaß (zw. Clustern)
- Nearest Neighbor: Absoluter Abstand zwischen zwei nächsten Nachbarn der beiden Cluster
- Farthest Neighbor: Zwei Punkte die am weitesten von einander entfernt sind = Abstand von beiden Clustern
Bewertung
- Einfach
- Besser geeignet als k-means Clustering, wenn k nicht bekannt, aber gewisse Aussagen über die Form der Cluster getroffen werden können (d, t)
- Unabh. von Initialwerten
COBWEB
- Begriffliches Ballungsverfahren
- kontextsensitives Verfahren (klassische kontextfrei)

- Ziel: Wie können Beispiele in Klassen bezüglich ihrer Ähnlichkeit
geordnet werden? - Aber trotzdem: keine Klasseninformationen gegeben
- Lernen durch inkrementelles Aufbauen und Anpassen eines Strukturbaums
Grundprinzip
- Nur nominale Attribute
- Repräsentation der Begriffshierarchie als Baum, Blätter sind die speziellsten Begriffe
- Jede Verzweigung innerhalb des Baumes steht für eine Einteilung der Unterbäume in verschiedene Kategorien
Hey,
bin zufällig auf diese Seite gestoßen, da ich gerade für ML1 selbst eine Zusammenfassung schreibe und ich näheren Input für Bootstrapping gesucht habe.
Gefällt mir sehr gut, was du hier gemacht hast und ich werde deine Arbeit in meinen „Lernprozess“ mit einbeziehen. 🙂
VG, Dominic